The Startup DDoS Stack: Why Agent-First Detection Beats Scrubbing Contracts
"The Business Case Our team has seen too many startups overpay for bulky, slow-to-implement protection or underinvest and eat the cost of downtime. Flowtri..."
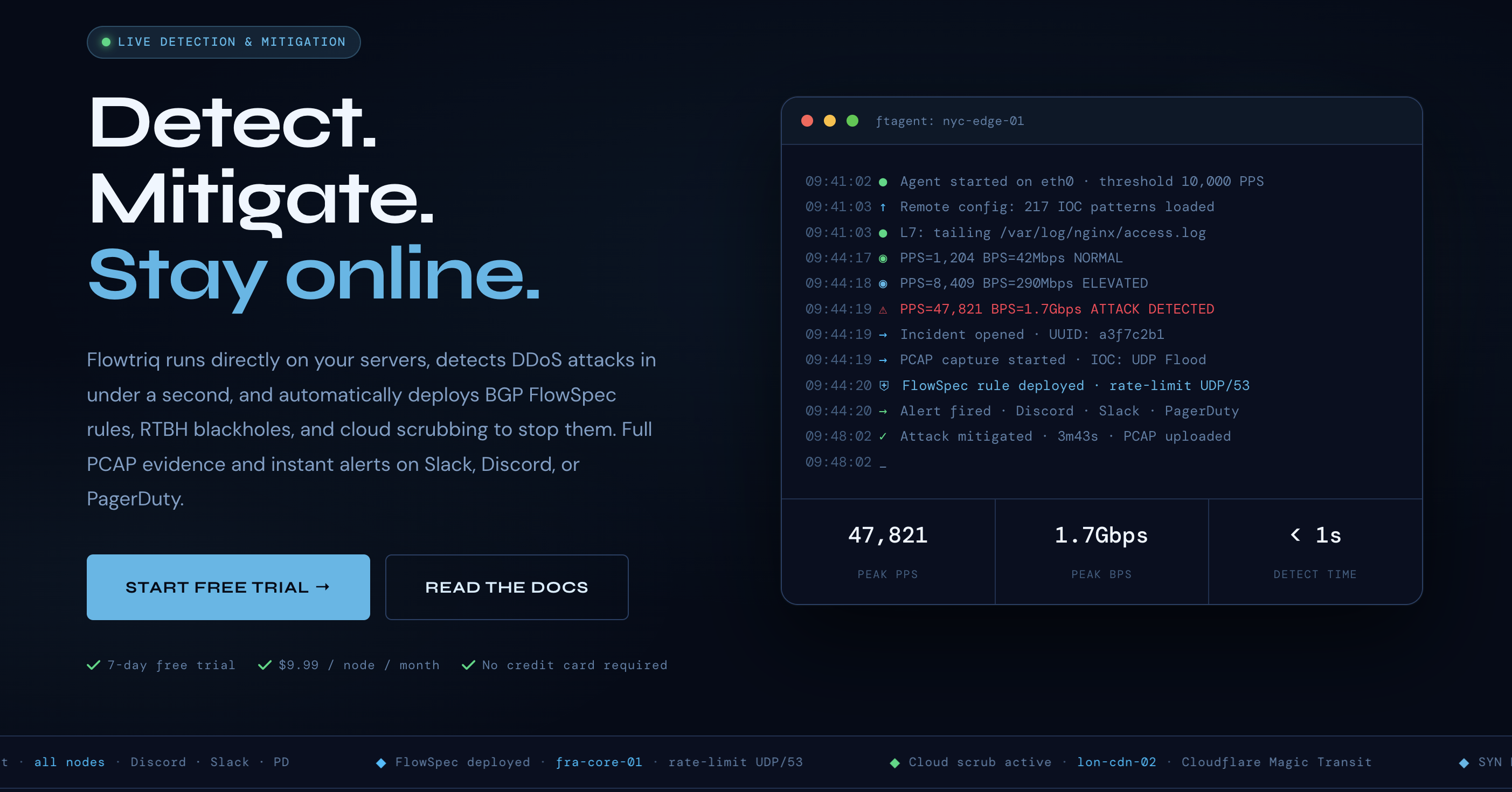
Stop Letting DDoS Hijack Your Quarter: A Fast Path to Resilient Revenue
You know the drill—alerts explode, support tickets pile up, your status page lights red, and your roadmap goes on pause while the team scrambles to deflect a flood they didn’t cause. Flowtriq is a lightweight, agent-based DDoS detection and auto-mitigation platform that spots and stops attacks in under a second, before customers notice. For startup leaders, the bottom line is simple: protect revenue, preserve brand trust, and keep shipping.
The Business Case
Our team has seen too many startups overpay for bulky, slow-to-implement protection or underinvest and eat the cost of downtime. Flowtriq’s economics flip that script. At $9.99/node/month (or $7.99 annual), with no traffic surcharges or per-alert fees, the model scales with your infrastructure—not your worst day. Sub-second detection and automated runbooks compress MTTD/MTTR from minutes to seconds, protecting transactional throughput, ad spend efficiency, and live user sessions where churn risk spikes during outages.
Beyond direct revenue protection, Flowtriq improves your posture with immutable audit logs, full PCAP capture on every incident, and attack profiles for post-mortems—useful for security reviews, enterprise sales, and board reporting. Its dynamic baseline learning reduces tuning toil, and multi-channel alerting (Slack, PagerDuty, OpsGenie, SMS) aligns incident response with your existing on-call rhythm. For startups competing against established brands, this is a brand-forward tool: the included status pages mean transparent, credible comms during turbulence. Our community’s Stack Showcases echo the same result—fewer firefights, more focus on growth.
Key Strategic Benefits
- •
Operational Efficiency: Automated detection and mitigation remove manual threshold babysitting and late-night scrambles. Runbooks chain response steps (BGP FlowSpec, RTBH, or cloud scrubbing) so your SREs manage by exception, not by guesswork.
- •
Cost Impact: Flat-rate, per-node pricing avoids surprise bills tied to attack volume. Many teams can defer or right-size expensive scrubbing-only contracts, redeploying budget to product velocity without compromising protection.
- •
Scalability: Multi-node management makes it feasible to secure edge nodes, game servers, and microservices without a new vendor negotiation every time you add capacity. Dynamic baselines adapt as your traffic grows, cutting down ongoing tuning.
- •
Risk Factors: Agent-based protection assumes Linux hosts and minimal overhead acceptance. Effective BGP FlowSpec or RTBH requires coordination with your ISP or upstream; cloud scrubbing integration (e.g., Cloudflare Magic Transit) may require separate contracts. As with any automation, false positives must be monitored during the first weeks.
Implementation Considerations
We’ve found a two-week rollout is realistic for most startups. Day 0–2: deploy the Python ftagent across a handful of representative nodes (API, auth, game lobbies, payments) and verify packet capture and dashboard visibility. Day 3–5: define escalation policies by risk tier—e.g., initiate FlowSpec within 1s, fail to RTBH at 5s, then path to cloud scrubbing at 10–15s for tier-1 endpoints. Day 6–10: integrate alerts with Slack/PagerDuty, run tabletop exercises, and validate status-page messaging for incident comms. Day 11–14: expand agent coverage, finalize runbooks, set on-call acceptance criteria.
Prerequisites: Linux servers, Python-based agent install permissions, and either ISP cooperation for FlowSpec/RTBH or existing accounts with scrubbing providers such as Cloudflare Magic Transit, OVH VAC, or Hetzner. Resource load: one SRE plus a security lead can own deployment; product/CS should co-own status-page protocols. Change management: start with monitor-only, then enable staged mitigations to calibrate baselines and minimize false positives.
Competitive Landscape
In our Alternative Picks analysis, Flowtriq is a contrarian take versus appliance-first or scrubbing-only stacks. Where fully managed scrubbing services like Cloudflare Magic Transit (https://www.cloudflare.com/magic-transit/) and Akamai Prolexic (https://www.akamai.com/products/prolexic) excel at absorbing volumetric attacks, they often carry higher base fees and traffic-based pricing. Hardware-led approaches like Radware DefensePro (https://www.radware.com/products/defensepro/) and NETSCOUT Arbor (https://www.netscout.com/product/arbor) demand capex and network engineering lift. Cloud-native shields like AWS Shield Advanced (https://aws.amazon.com/shield/advanced/) and Google Cloud Armor (https://cloud.google.com/armor) are strong if you’re all-in on a single cloud and primarily need L3/L7 within that perimeter.
Flowtriq’s edge: lightweight agent, sub-second detection at the host, and flat-rate economics, plus optional escalation to scrubbing partners. For hybrid or multi-cloud startups—or game/e-commerce workloads straddling bare metal and cloud—this mix offers resilience without locking you into one vendor’s network.
Recommendation
Our team recommends a 30-day phased pilot. Week 1: deploy Flowtriq on 10–20% of nodes, baseline traffic, and simulate attacks. Week 2–3: enable auto-runbooks for tier-1 services; integrate with Slack/PagerDuty and status pages. Week 4: compare incident metrics (MTTD, MTTR, false positive rate) and projected downtime savings against current spend on scrubbing and on-call. If metrics hold, negotiate an Enterprise plan for 50+ nodes with custom IOC libraries and extended PCAP retention. Build your stack. Stand out.
Contrarian Takes: If you’re already paying for a premium scrubbing contract, keep it—but let Flowtriq handle first-response and only escalate when needed. That’s the stack efficiency our community keeps showcasing.
Ready to order?
PLACE ORDER →